How Does Google Store All of its Data?
 Ever wonder how Google manages all their information? Imagine Gmail, it has to keep track of the billions of emails that get sent out each day regardless of whether or not it is spam.
Ever wonder how Google manages all their information? Imagine Gmail, it has to keep track of the billions of emails that get sent out each day regardless of whether or not it is spam.
A Database?
My first thought was a database. But if you think about it, if e-mails were stored in a single database table, it would have billions of rows added each day. This just isn’t possible nor is it efficient when performing a search. So Google cannot possibly store their data in a database… at least not in the traditional MySQL sense.
After a bit of digging around, I found an interesting document written by some of Google’s main architect that describes their file system in great detail. It turns out Google uses a distributed file system spread over many machines. It offers huge storage (hundreds of terabytes) over thousands of machines and thousands of disks.

The advantage of this type of system is redundancy and low cost. Their servers are not top of the line but clustering many of them together creates a highly cost-effective file system.
It’s what Yahoo Does
The owner of the largest database in the world, Yahoo!, takes on a similar approach: clusters of cheap computers that form a distributed file system. In fact, if a computer breaks down, it’s usually cheaper and faster to throw away the computer and replace it with a new one than it is to repair it.
So if you have a bunch of old computers sitting around at home, don’t throw them out just yet… you could create your own distributed file system!
Courtesy: http://www.jonlee.ca
Life of a Google Query
Technology Overview
the “perfect search engine,” defined by co-founder Larry Page as something that, “understands exactly what you mean and gives you back exactly what you want.” To that end, we have persistently pursued innovation and refused to accept the limitations of existing models. As a result, we developed our serving infrastructure and breakthrough PageRank™ technology that changed the way searches are conducted.
From the beginning, our developers recognized that providing the fastest, most accurate results required a new kind of server setup. Whereas most search engines ran off a handful of large servers that often slowed under peak loads, ours employed linked PCs to quickly find each query’s answer. The innovation paid off in faster response times, greater scalability and lower costs. It’s an idea that others have since copied, while we have continued to refine our back-end technology to make it even more efficient.
The software behind our search technology conducts a series of simultaneous calculations requiring only a fraction of a second. Traditional search engines rely heavily on how often a word appears on a web page. We use more than 200 signals, including our patented PageRank™ algorithm, to examine the entire link structure of the web and determine which pages are most important. We then conduct hypertext-matching analysis to determine which pages are relevant to the specific search being conducted. By combining overall importance and query-specific relevance, we’re able to put the most relevant and reliable results first.
- PageRank Technology: PageRank reflects our view of the importance of web pages by considering more than 500 million variables and 2 billion terms. Pages that we believe are important pages receive a higher PageRank and are more likely to appear at the top of the search results.
PageRank also considers the importance of each page that casts a vote, as votes from some pages are considered to have greater value, thus giving the linked page greater value. We have always taken a pragmatic approach to help improve search quality and create useful products, and our technology uses the collective intelligence of the web to determine a page’s importance.
- Hypertext-Matching Analysis: Google also analyzes page content. However, instead of simply scanning for page-based text (which can be manipulated by site publishers through meta-tags), our technology analyzes the full content of a page and factors in fonts, subdivisions and the precise location of each word. We also analyze the content of neighboring web pages to ensure the results returned are the most relevant to a user’s query.
Google innovations don’t stop at the desktop. To give people access to the information they need, whenever and wherever they need it, we continue to develop new mobile applications and services that are more accessible and customizable. And we’re partnering with industry-leading carriers and device manufacturers to deliver these innovative services globally. We’re working with many of these industry leaders through the Open Handset Alliance to develop Android, the first complete, open, and free mobile platform, which will offer people a less expensive and better mobile experience.
Life of a Google Query
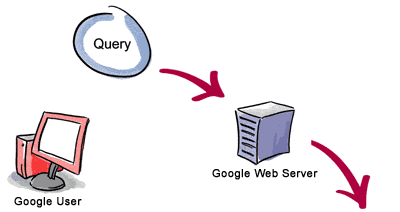
The life span of a Google query normally lasts less than half a second, yet involves a number of different steps that must be completed before results can be delivered to a person seeking information.
|
|
|||
3. The search results are returned to the user in a fraction of a second. |
1. The web server sends the query to the index servers. The content inside the index servers is similar to the index in the back of a book – it tells which pages contain the words that match the query. | ||
 |
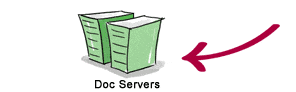
2. The query travels to the doc servers, which actually retrieve the stored documents. Snippets are generated to describe each search result. |  |
 |
||
-
Recent
- Top IT skills that can get you a better job
- Madurai’s traffic cops to get booths with ACs
- Facebook opens office in Hyderabad, India
- Kill IE6 says Industry, No says Microsoft!!!
- Infosys looking at overseas acquisitions
- Satyam Computers is now Mahindra Satyam
- Microsoft To Launch Free Anti-virus Named ‘Morro’ Soon
- Sourav Ganguly promises Rs 60 lakh for Cyclone Aila victims
- How Does Google Store All of its Data?
- Infosys Layoff – The IT giant Infosys Technologies fires 2100 employees
- Happy Rahman thanks mother, God at Oscars gala
- AR Rahman gets 2 Oscars for Slumdog’s music
-
Links
-
Archives
- April 2010 (2)
- March 2010 (1)
- October 2009 (2)
- June 2009 (3)
- May 2009 (1)
- April 2009 (1)
- February 2009 (3)
- January 2009 (9)
- December 2008 (16)
- November 2008 (32)
- October 2008 (34)
-
Categories
-
RSS
Entries RSS
Comments RSS
